ChatGPT and the new Deepseek-R1 are generative AI’s that are all the rage now. The most common form of these generative AI models is as a “ChatBot” that you can carry on a conversation with. We refer to these AI’s as “generative” because this enables users to quickly generate new content based on evaluating inputs over the course of a conversation.
By asking many questions in such a ChatBot, we can obtain results that mimic deductive reasoning.
The Ollama website is an open source project that provides many open source AI models that you can self-host. Ollama stands for (Omni-Layer Learning Language Acquisition Model). One of the distinguishing features of Ollama is its ability to run LLMs locally.
In this tutorial, I will show how to self-host the Open Web UI with Ollama as the backend as a docker application in an Incus container. Ollama Model sizes support varying numbers of parameters from 1B to 671B for the largest deepseek model. Home Lab users will generally want to run models with 7 billion or less parameters because of the intense CPU resource requirements of larger models.
Models with more parameters produce better results and models with fewer parameters are faster and require lesser CPU resources.
I hosted my ChatBot in an Incus container on my desktop because my desktop Minisforum UM-890 Pro has a Neural Processor Unit (NPU) better suited for AI workloads. I use an Incus container for application isolation and security.

I start by opening a terminal and creating an incus container. If you are unfamilar with Incus, be sure to watch my tutorial Incus Containers Step by Step. I present my container to the main LAN using techniques presented in that video.
incus launch images:ubuntu/24.04 WebAI -p default -p bridgeprofile -c boot.autostart=true -c security.nesting=true
Connect to a shell prompt in the container.
incus shell WebAI
Update the respositories for the new container.
apt update
Install dependencies and also docker:
apt install curl openssh-server nano net-tools -y
curl -sSL https://get.docker.com | sh
Add a user account and put the user account in the sudo and docker groups.
adduser scott
usermod -aG sudo scott
usermod -aG docker scott
Move to the new account.
su - scott
Make a folder for the application and move into the folder.
mkdir openai
cd openai
Edit a compose file for the docker application.
nano compose.yml
Insert the following text.
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
restart: unless-stopped
container_name: open-webui
depends_on:
- ollama
volumes:
- ./config:/app/config # Persist configuration
- ./data:/app/data # Persist user data (database)
ports:
- 80:8080
environment:
- OLLAMA_BASE_URL=http://ollama:11434 # Connect Open WebUI to Ollama
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- ./models:/root/.ollama # Persist downloaded models
Save the file with a CTRL O and enter and then CTRL X to exit the nano editor.
Download the container overlays for the open-webui frontend and the ollama backend and start the application.
docker compose up -d
Change the protections for the models folder once the application starts.
sudo chmod -R 777 ./models
Check to see that the application is in the healthy state.
docker ps

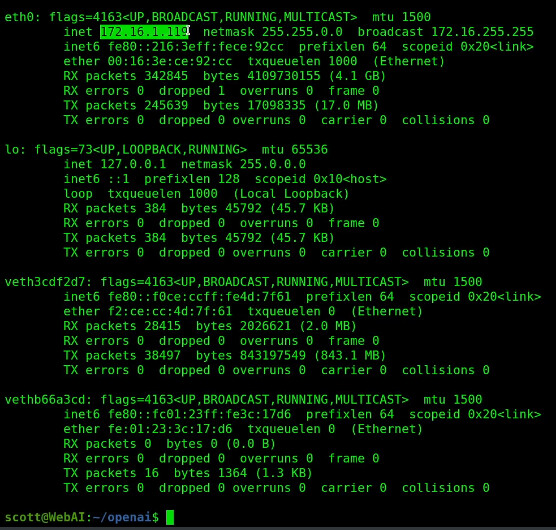
Check the address of eth0 which should be an address on your main LAN.
ifconfig
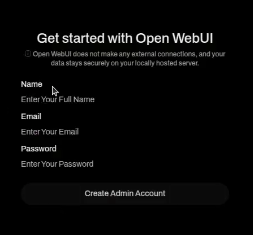
If you go to that address in your web browser, you should see the following screen.

Click “Get Started” and enter your name, email, and desied password. This is the administrative account and the email is your username,
Next you will see a splash screen showing the version number and brief release notes.
Click on “Okay, Let’s Go!” and you will see the following.
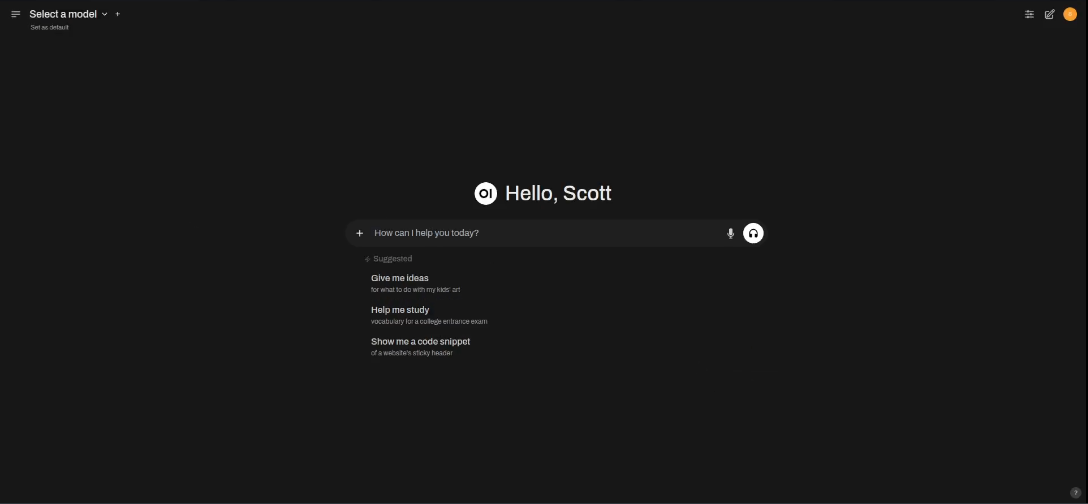
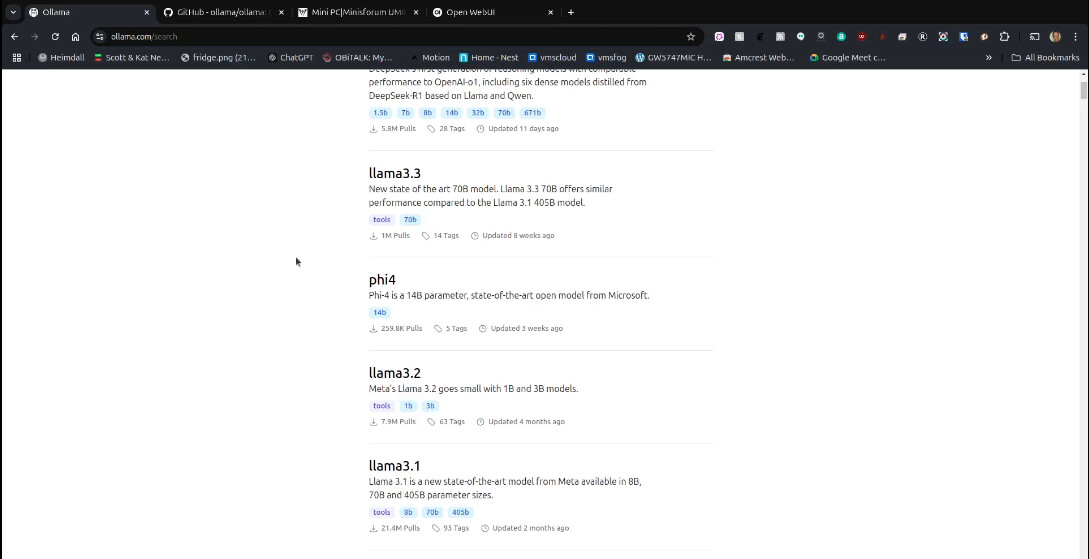
Before you can actually use your AI ChatBot, you must download a model from Ollama and you will want to visit Ollama to browse the various models and the number of parameters for the selected model.
In the video, I started with “ollama3.2”:
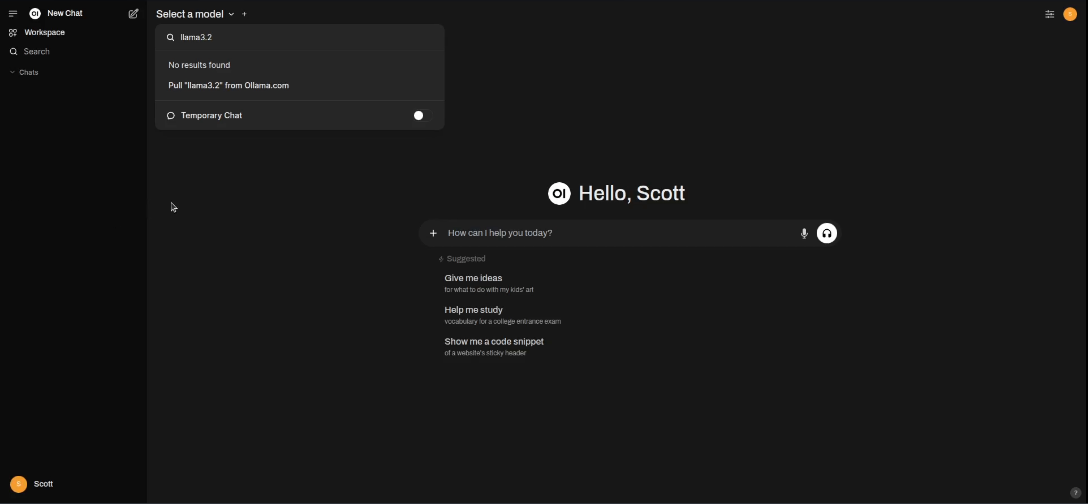
Once you type in the name of the model, you click the “pull” option to download the model. Ollama3.2 is a 3 billion parameter model which is a reasonably small model that should run fairly quickly.
Once the model is loaded and verfied, click the drop down menu, select the model and optionally set your model as the default model.
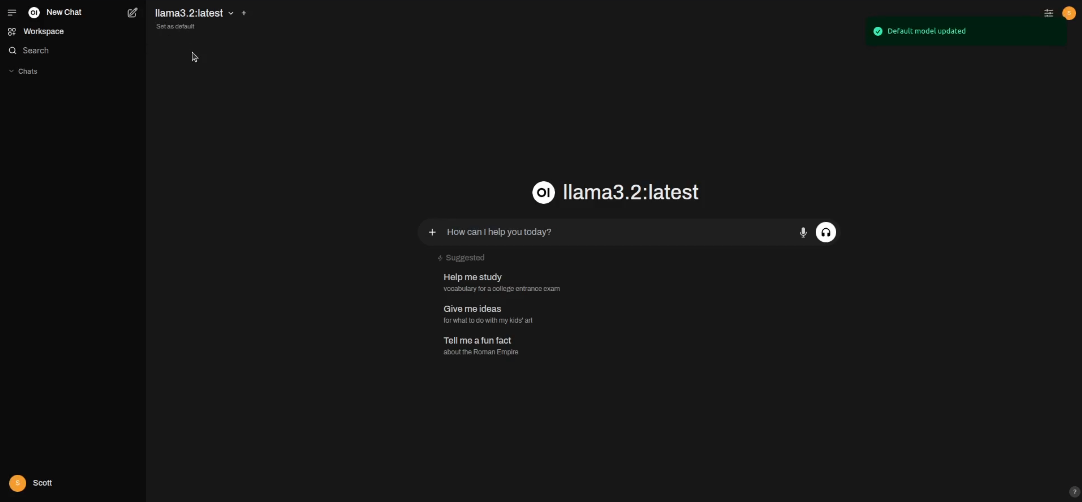
Back on the Ollama page, you can see the model names and sizes.
As shown in the video, you can now start asking your model questions and all of your queries and answers are completely private.
There’s been a lot of controversy about using the Chinese “deepseek-r1” because the data might be mined by the Chinese government. The deepseek-r1 model is open source and we can download it from ollama making it completely private when we host in the Home Lab.
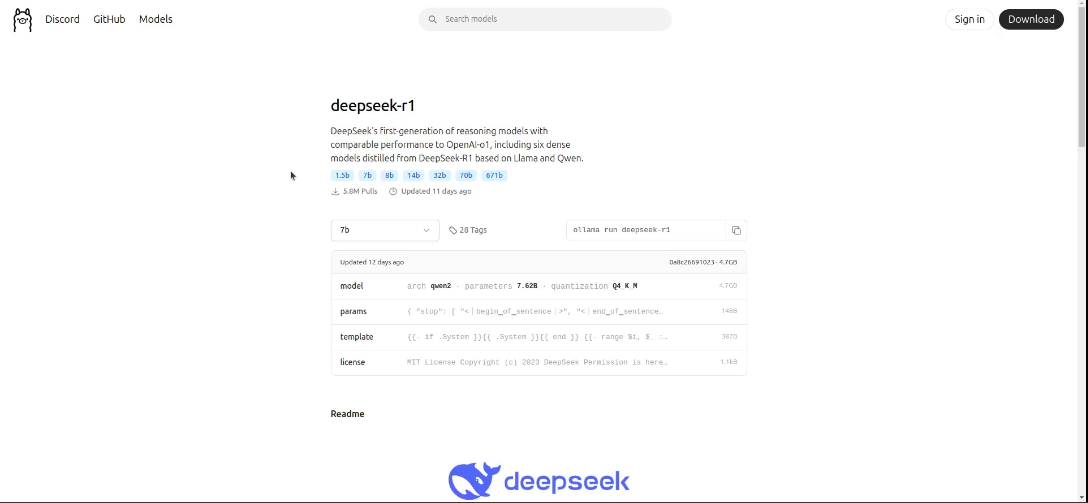
The smallest deepseek-r1 model is only 1.5b parameters, whereas the largest is 671b parameters. The 671b parameter model would require a computer well out of the financial affordability of a home user. You can probably run the 1.5b, 7b and maybe 8b parameter models within reason depending on your host computer.
In my example, I ran the deepseek-r1 model with 7 billion parameters and it took 2.5 minutes to answer a simple question on my Minisforum UM-890 Pro. So, smaller models would be better unless you don’t mind waiting.
Realize that AI ChatBots are not mining information from the Internet and have no live access to the net. Instead, all data is embedded in the respective model. So, you can’t ask an AI ChatBot what the current weather is.
The models that I have tested and had reasonable results with are:
llama3.2
llama3.2:1b
deepseek-r1:1.5b
deepseek-r1
ZimaBlueAI/MiniCPM-o-2_6
llama3:8b
I see clear privacy advantages to a self hosted AI ChatBot in the Home Lab. Try this out and let me know on the ScottiBYTE RocketChat Server how your experiences have been.